
Some of the most important decisions in SEO are based on search volume data. We use it to compare keywords, to guide our content strategy, and to make traffic projections. We may even use it to predict conversions and revenue. And yet, it is one of the least reliable pieces of data to exist in SEO.
If you ever tried comparing search volume data across keyword tools, you probably know that the numbers are usually very different. Like, surprisingly different. For example, here is what happens when I research the same keyword across some of the most popular SEO tools:
How do SEO tools calculate search volume?
Since Google has a monopoly on search, it is the only company that actually knows how often something is searched online. No other company can possibly collect that much data and all SEO tools without exception have to ask Google for their search volume numbers. So, whenever you use an SEO tool to check search volume, it is based on the data provided by Google Ads (Keyword Planner).
Except, we already know that different keyword tools show very different search volume numbers. The reason is that back in 2016, Google Ads had stopped sharing exact search volume numbers with free users and switched to sharing volume buckets instead. So, if in the past the information was presented like this:
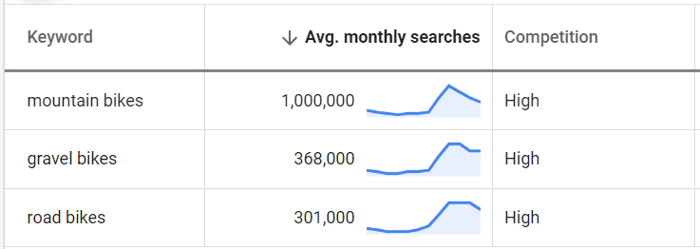
Today, unless you are running paid campaigns through Google Ads, all you get is a pretty large bucket, like this:
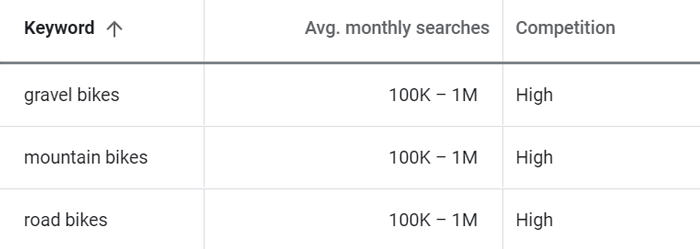
Buckets are clearly a problem because they make it difficult to compare keywords. For example, according to Google, gravel bikes, mountain bikes, and road bikes fall within the bucket of 100K-1M searches per month. But what if I don’t have enough resources to work on both keywords? How do I choose which one to prioritize? What if one is actually searched 100K times per month and another one 999K times per month? It could make or break my business.
Faced with this change in Google’s data, keyword tools were looking for a way to supply their clients with more usable numbers. In this quest, they started to collect search volume data from additional sources and use it to go from buckets to specific readings. Here are some of the data sources currently employed by keyword tools:
Clickstream data
Apart from Google, our online behavior is monitored by a whole host of plugins, browsers, browser extensions, antivirus programs, and internet providers. Most user agreements that we accept so blindly, allow them to collect anonymized user data — clickstream data.
The problem with these apps is that none of them have the user base and the access of Google. Individually, each of them can only observe a very small part of the web. This is where data aggregators come in. These are the companies that buy clickstream data from multiple sources, merge it, clean it, and sell it to third parties, like SEO tool developers.
Now, the data bought from aggregators is nowhere near the data from Google in terms of volume and reliability, but it is still useful. When cross-referenced with Google’s search volume buckets, it can indicate which keywords are more popular or less popular relative to other keywords. Basically, it helps keyword tools to make an educated guess of where the search volume falls within the buckets provided by Google.
Google Ads forecasts
Another type of data that may hint at more specific search volumes is Impressions calculated in Keyword Planner’s Forecasts. Forecasts is the tab in Keyword Planner, where you can see how many impressions your ad would get per given spending:
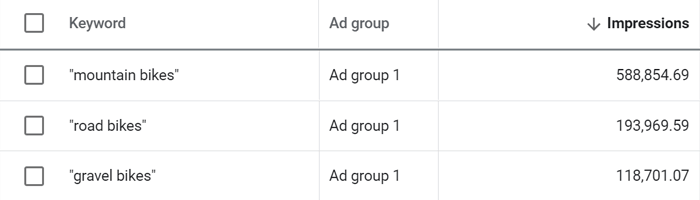
The problem with forecasted impressions is that they have too many moving parts. The numbers depend on things like your bid preferences, competition, search partner policies, your own ad history or a lack of thereof, and it may or may not include search volumes for other similar keywords. In the end, impressions do not equal organic search volume, but they are a good indicator of which end of the bucket you should aim for.
User data
Finally, some keyword tools may allow users to import search volume data from other sources. One way it can be done is via integrations with the user’s Google accounts. For example, if you run paid ads with Google you can connect your Google Ads account to your keyword tool and source reliable search volume data directly from there.
What are the common problems of search volume data?
We’ve established that keyword tools are not happy with Google data, now let’s take a closer look at some of the problems that they are trying to solve.
Averages
By default, Google calculates search volume as a monthly average of the past twelve months. The problem with the average value is that it does not necessarily reflect the latest information. If the search term is seasonal, for example, or if it’s recently been gaining or losing popularity, then its current search volume may be much higher or lower than its annual average.
Luckily, Google allows calibrating its data and we can request the search volume for any time period. Some keyword tools may choose to use shorter periods — their search volume data will be more current, but it will also be more volatile throughout the year.
Groupings
Google would often group similar keywords together and assign them the same search volume. In the image below, for example, Google considers road bike and road bikes to be one and the same:
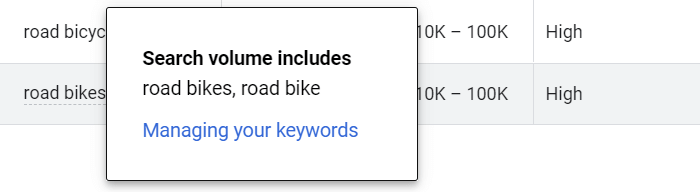
Keywords may be grouped when Google considers the differences between them to be insignificant and when variations have an identical intent. As a general guide, here are the most common cases when Google would group keywords:
| Type of grouping | Example |
|---|---|
| Typos | Bianchi bikes / Bianki bikes |
| Singular/plural forms | road bike / road bikes |
| Abbreviations | NYC / New York City |
| Reordered words | winter jacket / jacket winter |
| Function words | mens jackets / jackets for men |
| Synonyms | cycling trail / biking trail |
Whether it is a problem or not is up for debate. Some say that groupings may mistakenly merge some terms with different search intent and it’s best to view each keyword variation separately. Others say that this would be a waste of time and if Google merges terms, then it means they are treated identically in search.